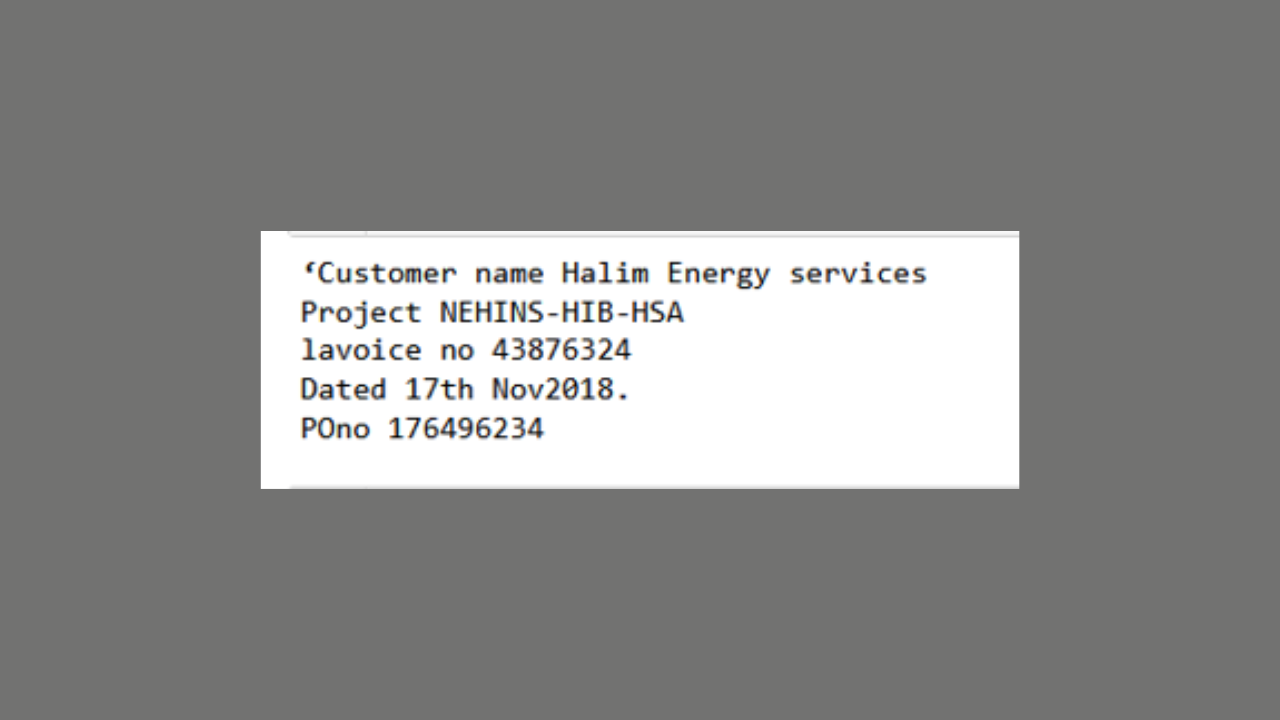
OCR Model for Text Recognition
This project focuses on developing an Optical Character Recognition (OCR) model using the Tesseract library in Python. The model is trained on a diverse dataset of images containing text, enabling accurate text extraction. The OCR Tesseract Model has applications in document digitization, automated data entry, text translation, and information extraction, streamlining workflows and improving efficiency in various industries.
Category:
Sub-category:
Computer Vision
Optical Character Recognition (OCR)
Overview
This project focuses on developing an Optical Character Recognition (OCR) model using the Tesseract library. OCR is a technology that enables the extraction of text from images or scanned documents. The Tesseract library, coupled with Python, provides a powerful and flexible solution for implementing text recognition tasks. The model is trained on a large dataset of diverse images containing text, allowing it to accurately recognize and extract text from various sources.
Description:
The OCR Tesseract Model project leverages the Tesseract library to create a robust model capable of accurately recognizing and extracting text from images. The training dataset comprises a diverse collection of images that contain text, including scanned documents, product labels, and signboards.
To train the model, the Tesseract library's OCR engine is utilized along with Python programming. The images in the training dataset are preprocessed to enhance text visibility and remove any noise or artifacts that may hinder accurate recognition. The Tesseract engine applies advanced techniques such as character segmentation, feature extraction, and language modeling to analyze the images and extract the underlying text.
The OCR Tesseract Model has a wide range of practical applications across industries. It can be employed in document digitization, automated data entry, text translation, and information extraction tasks. By accurately extracting text from images, the model simplifies workflows, reduces manual effort, and improves efficiency in various domains such as administrative tasks, archival systems, and information retrieval.
Programming Language:
Python OCR
Library:
Tesseract